Here is the short version. To train AI on your writing style, you give it enough of your real writing for it to build a model of how you write, then you draft from that model and correct it until the output reliably sounds like you. In practice that is four steps: gather the writing you already have, let the tool extract your style patterns, draft and check the voice match score, and give feedback so it tightens over time. This is the practical, step-by-step guide. If you want the model-level version (why prompting a general assistant hits a ceiling, and how fine-tuning and voice profiling differ under the hood) that is a separate piece: how to train AI on your writing voice: the technical breakdown. (Named-tool note: ChatGPT and other general assistants are named here as the tools people actually use; audenAI, the brain inside VoiceMoat, is named as a product, never as a backend model.)
What does it mean to train AI on your writing style?
It helps to be precise, because two very different things get called the same name. Telling an AI about your style means describing it: you paste a few examples or write custom instructions, and the model reads that description in its context window every time. Training AI on your style means the tool reads a large body of your actual writing and builds a model of the patterns in it, then generates from that model as its starting point. The first is a note the model glances at; the second is a baseline the model writes from. That distinction is the whole reason a trained tool holds your voice while a prompted one drifts back to its generic average.
Your writing style is not your topic and it is not your formatting. It is the texture underneath both: the words you reach for, the rhythm of your sentences, how you open and close, the references you make. Those patterns are measurable, which is the part that makes training possible at all (the field that studies measurable writing style is stylometry). A tool models them across a set of named signals, scores each draft against your baseline, and refuses output that drifts too far. The framework-level reference for which signals matter is the 10 signals of voice. For the broader concept this sits inside, what separates personalized AI content from the generic default, see personalized AI content. For the Claude-specific version, using Projects and Styles to hold your voice, see how to make Claude write in your voice.
Step 1: Gather the writing you already have
The first step is the one people overthink. You do not sit down and write training samples. You point the tool at the back catalog you already published, the posts, replies, threads, and images you have been producing for months or years without ever thinking of them as data. Most active creators already have more than enough. The target is roughly 100 to 200 pieces of your real writing, which is the difference between a sample that describes your style and a corpus that defines it. A few examples in a prompt show the model a thin slice; a few hundred pieces show it the patterns that actually repeat. Here is what each kind of writing teaches the tool.
| What you feed it | What it teaches the AI about your style |
|---|---|
| Your posts | Your default cadence, vocabulary, and the hooks you open with |
| Your replies | Your conversational register: how you sound off the cuff, not just when polished |
| Your threads | Your long-form structure: how you build and pace an argument |
| The images you share | Your visual references and the captions that frame them |
| The whole profile together | The patterns that repeat across all of it, which is what a style actually is |
Volume is doing real work here, not padding. A model trained on a handful of examples can imitate the surface of your style for a sentence or two before its own defaults reassert; a model built on your full profile has enough signal to hold the pattern across a whole draft and across a long session. The mechanical reason a thin sample reverts is covered in why all AI-written tweets sound the same. For Step 1, the takeaway is simpler: the writing you need already exists, and the job is to point the tool at it rather than to produce more.
Step 2: Let the AI extract your style patterns
This is the step that sounds technical and is not, at least not for you. You are not labeling data, tuning a model, or writing code. A purpose-built tool reads your corpus and extracts your style into a structured profile across a set of measurable signals: cadence, hooks, tone, rhythm, vocabulary, structure, length, openers, references, and sign-offs. Those 10 signals are the dimensions a tool can actually score against, and the canonical breakdown of each is in the 10 signals of voice. The extraction runs once on the writing you connected in Step 1, and the output is a baseline: a model of how you write that the tool generates from, rather than a paragraph of instructions it has to re-read. Here is the whole pipeline, end to end.
- Step 1
Connect your writing
your existing posts, replies, threads, and images
- Step 2
Extract the style signals
the tool models your patterns across the 10 signals
- Step 3
Build your baseline
a model of how you write, not a prompt about it
- Step 4
Draft from the baseline
output starts in your register, not the generic average
- Step 5
Score every draft
a voice match score against your baseline, with a ship-ready floor
The prompting route has no extraction step, which is exactly why it tops out. When you paste examples into ChatGPT, nothing builds a baseline; the samples sit in the context window as a description, and each token is still drawn mostly from the model's trained average. The step-by-step version of that prompting method, and the ceiling it hits, is in how to make ChatGPT write tweets in your voice. Voice profiling exists precisely because the extraction step is the thing that moves the ceiling.
Step 3: Draft and check the voice match score
Once your baseline exists, you draft normally, and every draft comes back with a number: a voice match score that measures how close the output lands to your baseline. This is the part that turns voice from a feeling you eyeball into something you can manage. A draft at 94 percent reads like you; a draft below your floor gets refused at the model level instead of handed to you to fix. The common AI tells sit on a taboo list by default, so the over-used vocabulary in the words AI overuses and the em-dash signature do not leak into output that is supposed to sound like you.
The score matters because you cannot manage what you cannot see. With a prompted assistant, the only quality gate is your own attention: you read the draft, decide whether it sounds right, and ship or rewrite. That works until you are tired, rushed, or producing at volume, which is exactly when generic drafts slip through. A measured baseline moves that judgment off your shoulders and onto the page, so the gate holds even on the days you are not reading closely.
Step 4: Give feedback so it keeps sounding like you
Training is not a one-time freeze. The last step is the feedback loop: you keep the drafts that land, correct the ones that miss, and the baseline tightens around your real patterns rather than around its first approximation of them. This is also what keeps the model current as your style evolves. Writers do not write the same way at 50,000 followers as they did at 5,000, and a baseline that updates as you write does not strand you in an old version of your voice. The failure mode this prevents has a name: voice drift, the slow slide toward a flatter, more generic register that most creators never notice until the recognition is gone.
What results should you expect?
Honest expectations matter, because a tool that promises to be you is overselling. Here is the realistic read. Most first runs land strong, in the 90s on voice match, because your full profile is a rich signal. Drafts need light edits rather than full rewrites, which is where the time actually comes back. The baseline holds across a long session instead of drifting after a paragraph or two. What it will not do is think for you. It drafts in your patterns; you still supply the ideas, the point of view, and the publish decision. Treat it as a writing partner that has read everything you have ever posted, not as an autopilot.
| What training your style does | What it does not do |
|---|---|
| Drafts that open and move the way you do | Think for you or supply your point of view |
| A measurable voice match score on every draft | Guarantee a viral post (voice is recognition, not reach) |
| A baseline that holds across a long session | Freeze your style in the past; it updates as you write |
| Light edits instead of full rewrites | Take you out of the loop; you still approve every post |
Can you train AI on your style with ChatGPT alone?
Partly, and it is worth being fair about it. With custom instructions, memory turned on, and a careful prompt, ChatGPT can carry your topics and a rough approximation of your cadence. But that is describing your style, not training a model on it, and the ceiling shows: prompted voice imitation tops out around 30 to 40 percent of your real voice on the first draft and degrades as the session runs, because memory stores facts about you rather than a model of how you write. If your real question is which approach to choose, the branded head-to-head is VoiceMoat vs ChatGPT, and the wider category comparison is ChatGPT vs specialized AI tools for personal branding. If your question is why the prompting ceiling exists at the model level, that is the technical breakdown.
How VoiceMoat trains AI on your writing style with no setup
VoiceMoat is built to do exactly the four steps above without asking you to touch any of the machinery. You connect your Twitter and LinkedIn accounts, and audenAI, the brain inside VoiceMoat, trains on your full profile of 100 to 200 posts, replies, threads, and images across the 10 signals of voice. There is no fine-tuning to configure and no code to write; the extraction is the product. Every draft then comes back with a voice match score against your baseline, 80 percent is the ship-ready floor, and the AI vocabulary cluster is refused by default. Here is the one-time setup, start to finish.
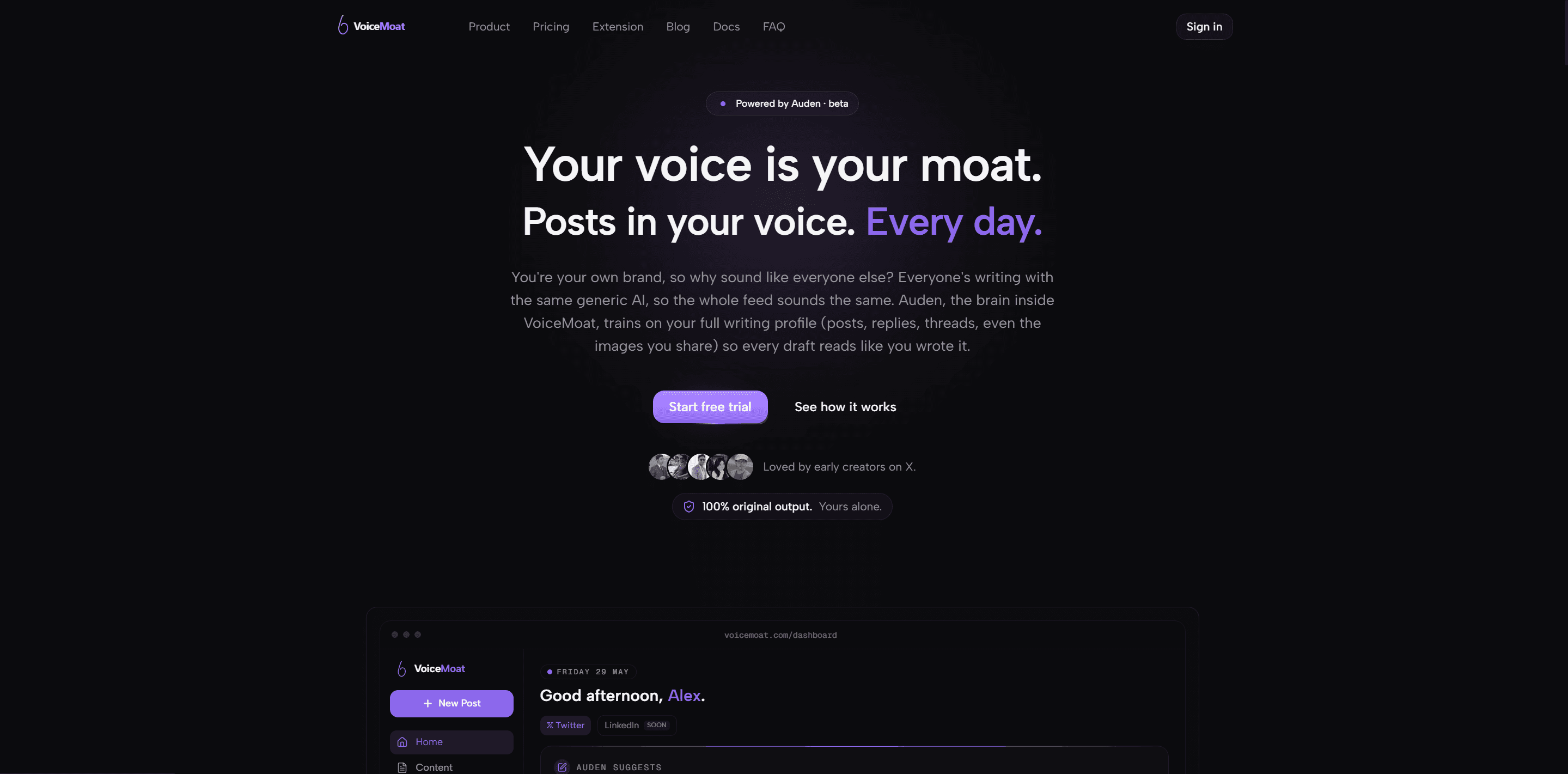
You can start free: the free plan includes one voice profile and the voice match score, with no credit card up front, so you can train audenAI on your own writing and judge the result before paying anything. Paid plans run from $35 a month when you need more volume and more voice profiles. If you want a structured way to put it through its paces, evaluating VoiceMoat in 7 days lays out a week-long test.
Is training AI on your style the same as voice cloning?
No, and the distinction is worth stating plainly. Voice cloning usually means synthesizing someone's likeness, often a spoken voice and sometimes without consent. Training AI on your writing style is the opposite setup: it is your own corpus, used with your consent, to draft in your own patterns, with you as the editor who approves or rejects every output. A trained tool does not act on your behalf or impersonate you; it drafts in your register and hands the result back for you to decide on. The product framing is voice-not-cloning for exactly this reason, and the longer treatment of where that line sits is in the technical breakdown.
The bottom line
Training AI on your writing style is not a research project. It is four steps: gather the writing you already have, let the tool extract your style signals, draft and check the voice match, and give feedback so it tightens. The thing that separates training from prompting is the extraction step, the one that builds a baseline from your real writing instead of a description it reads each time. Do that, and you get drafts that open and move the way you do, held steady by a number instead of your tired attention. In a feed where most content is now machine-shaped, that consistency is the asset. If you want to run the four steps without touching any of the machinery, start with audenAI. audenAI suggests. You decide.