The reply guy playbook: how to use AI for Twitter replies without sounding like a bot in 2026 is the question that surfaces when a creator who reply-guys at scale (5 to 10 voice-rich replies per day, the canonical smart reply guy strategy cadence) needs AI assistance to sustain the cadence without collapsing voice. The conviction-led answer is that reply tooling sits on a voice-corrosive-versus-voice-rich split, and the right side of the split is operationally non-negotiable for creators serious about the audience-relationship as the compounding asset. Reply automation at the voice-corrosive edge produces output the audience pattern-matches as a bot within scrolling distance; reply tooling on the voice-rich side puts the writer in the loop with voice-trained drafts the writer edits and ships. This piece walks the split, surfaces the inline Chrome extension workflow that makes voice-rich replies sustainable at cadence, shows three illustrative reply examples clearly labeled as constructed, and names the operational discipline that compounds reputational capital instead of collapsing it.
The framework-level read on why reply-driven growth compounds (and why the smart reply guy strategy is the most underrated cold-start growth pattern on X in 2026) is at the canonical reply-driven-growth piece. The deeper case against reply automation at the voice-corrosive edge is at how to grow on X without buying followers or engagement pods in 2026. The named-competitor head-to-head between the voice-rich-writer-in-the-loop reply approach and the automation-first-with-Telegram-approval reply category (Contagent) is at VoiceMoat vs Contagent in 2026: AI Twitter tools, compared head-to-head. The architectural backdrop for why reply quality compounds in 2026 specifically is at Phoenix's 19 engagement heads with the reply head as the heaviest weight, and the dwell-firing patterns voice-rich replies trigger are at dwell time is the new like: the 4 dwell heads ranking your posts.
Why replies carry more weight on X in 2026
Replies are not a sidebar to the X growth model in 2026; they are increasingly the model. Two shifts put them there. First, reach collapsed for ordinary posts: when the median non-Premium account sees roughly 0% engagement on its standalone posts (the data read is at Twitter engagement is down in 2026: a data read), the reply becomes the highest-leverage way to reach an audience that already exists on someone else's post. A voice-rich reply on a larger account's post borrows that account's distribution for the cost of one genuinely good sentence, which is why reply-driven growth is the most underrated cold-start pattern on the platform.
Second, the ranking system weights the reply heavily. The reply head is the heaviest of Phoenix's 19 engagement heads, and a reply that earns a response, a profile visit, or sustained reading fires the dwell-time heads that compound a post's reach. That is the upside, and it is exactly why the voice-corrosive failure mode is so costly: a bot-shaped reply consumes the same slot and the same attention but earns the negative version of every signal the reply head rewards. The mechanism that makes replies the best cold-start growth pattern on X is the same mechanism that punishes automated replies hardest, so the tooling choice is not a preference, it is the difference between compounding and decaying.
There is a third reason, slower but more durable than the algorithm: replies are how a parasocial audience becomes a real one. A post broadcasts; a reply is a two-way move the original author and the onlookers both register as a relationship event. Over months, the writer who shows up in the replies of the same circle of accounts with specific, useful reactions becomes a known quantity in that circle, and known quantities get the follows, the quote-tweets, and the introductions that standalone posting rarely earns. This is the asset the voice-corrosive failure mode destroys: automated replies do not build relationship density, they spend it.
The voice-corrosive versus voice-rich split in reply tooling
Reply tooling in 2026 sits on a structural split. On one side: automation-first tooling that schedules replies, auto-engages based on keyword triggers, and runs reply volume into the 30-to-100-per-day range with low writer involvement per reply. On the other side: writer-in-the-loop tooling that surfaces voice-trained reply drafts on x.com itself, lets the writer edit each one in 10 to 30 seconds, and ships at the smart-reply-guy cadence of 5 to 10 voice-rich replies per day. The two sides produce different reputational-capital outcomes over months, and the difference is not subtle.
The voice-corrosive side fails because reply volume at scale produces patterns the audience pattern-matches as a social bot within a few weeks of observation. The audience does not need a detector tool to catch the pattern; the human-level pattern recognition is enough. A reply that arrives within 30 seconds of every post the writer targets, that uses the same three opening structures across all replies, that praises rather than engages, that lacks the writer's specific reaction to the specific post, reads as automation by structural signature. Once the audience has pattern-matched the pattern, every subsequent reply from that account reads through the automation filter; the parasocial-relationship asset degrades and the writer's later voice-rich replies fail to land because the audience is no longer reading them as voice-rich.
The voice-rich side compounds because each reply carries the writer's specific reaction to the specific post and the audience reads each one as a genuine engagement. The 5-to-10-per-day cadence is structurally compatible with reading the post carefully, drafting a reply that engages with the specific take, editing for voice, and shipping. The 30-to-100-per-day cadence is structurally incompatible with that workflow; at that volume, the writer is either auto-generating without editing (the voice-corrosive failure mode) or skimming so superficially that the replies devolve into generic praise (which the audience reads as adjacent to automation). The compounding direction reverses at the cadence boundary; the voice-first argument is that the boundary is real and serious creators need to land on the right side of it.
| Voice-corrosive | Voice-rich | |
|---|---|---|
| Cadence | Volume that drops the edit step, often 30+/day | 5 to 20/day, edit step held |
| Writer involvement | Low (auto-generated or skimmed) | High (read, draft, edit each one) |
| Register | Generic praise or templated openings | The writer's specific reaction to the specific post |
| Audience read | Pattern-matched as a bot within weeks | Read as genuine engagement |
| Reputational capital | Decays, and poisons later replies | Compounds over months |
| Example tooling | Automation-first reply plus auto-engagement | Writer-in-the-loop voice-trained drafting, inline on x.com |
How many replies a day, really? The 15-to-50 question
Most reply-guy guides land on 15 to 50 replies a day, and some push past 100. This playbook caps lower, at 5 to 10, and the gap is worth explaining because it is the most common objection. The disagreement is not really about a number; it is about what the number costs. The voice-corrosive failure mode is not triggered at a specific reply count, it is triggered the moment volume forces you to drop the per-reply edit step. For most writers that happens well below 50 a day, because reading a post carefully and editing a draft to weld it to that post takes attention, and attention does not scale the way a reply counter does.
Where the boundary sits is personal. A writer using the inline extension, with the edit step as a reflex, can often sustain 15 to 20 voice-rich replies a day without the quality dropping; that is the honest upper end. Beyond it, almost everyone is either auto-generating or skimming, which is the corrosive zone the 30-to-100 guides quietly normalize. So treat 5 to 10 as the safe default that builds the habit, 15 to 20 as the ceiling for a disciplined writer with good tooling, and anything above that as a signal that the edit step has silently been dropped. The number is downstream of the edit step, not the other way around.
One companion ratio the better guides converge on is roughly 70/30: about 70% of your X effort in replies, 30% in original posts. The replies build relationship density and borrow distribution; the original posts give the audience somewhere to land once a reply earns the profile visit. Reply-only accounts plateau because there is nothing to follow, and post-only accounts starve for reach. The reply cadence is the engine; the original posts are what convert the reach the replies generate.
The inline Chrome extension workflow that makes the cadence sustainable
The operational problem with voice-rich reply cadence is tab-switching. The natural reply workflow without inline tooling is: read a post on x.com, switch to a separate drafting tool, compose a voice-rich reply, copy the reply back to x.com, post. The tab-switch costs 60 to 90 seconds per reply by the time the writer has read the original carefully and composed in the drafting tool. At 5 to 10 replies per day, the tab-switch cost compounds to 30 to 60 extra minutes per day, which the writer cannot defend at the weekly time audit. The cadence collapses to 1 to 2 replies per day or the writer abandons the practice entirely.
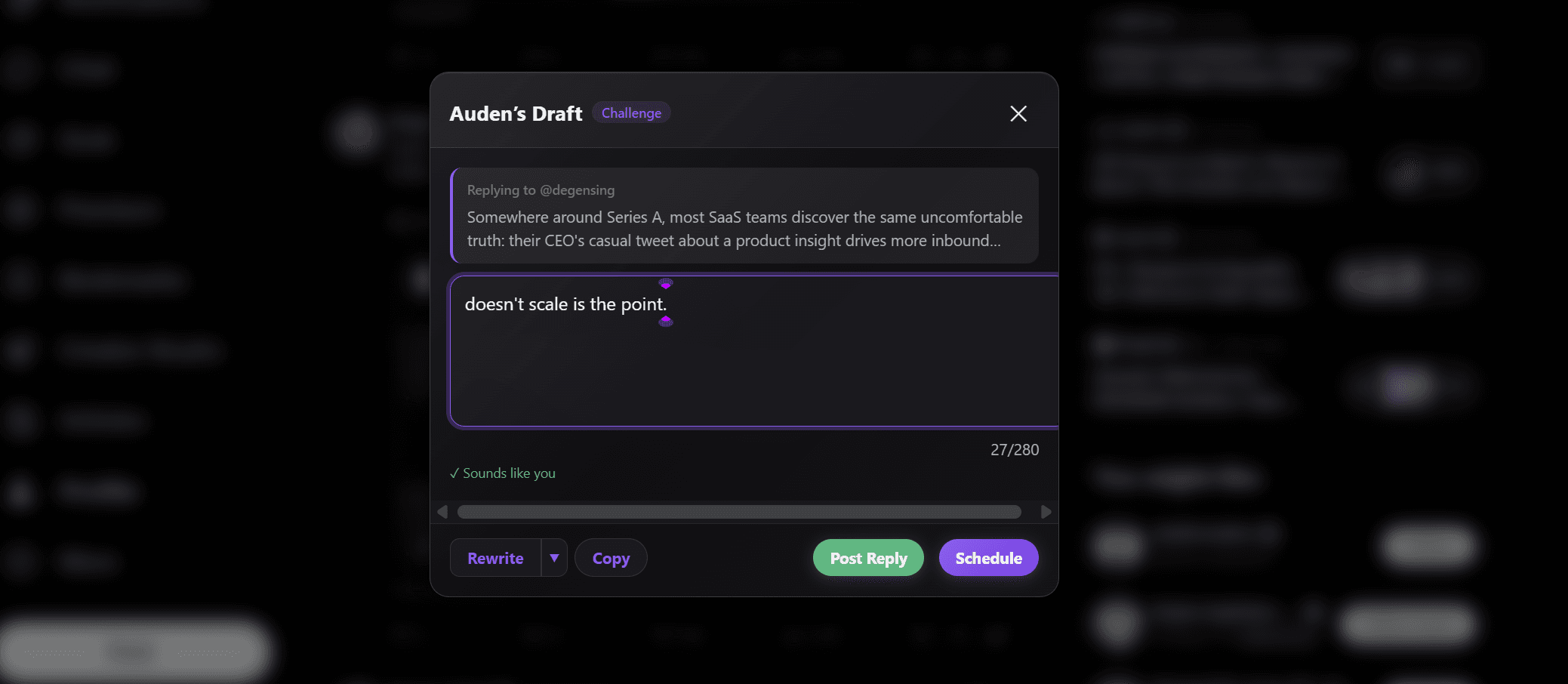
An inline Chrome extension fixes the tab-switch by surfacing voice-trained reply drafts directly on x.com. The workflow becomes: read the post on x.com, hover over the post, pick one of 12 tone presets, surface 3 voice-matched reply variants, select the closest, edit one or two phrases in 10 to 20 seconds, post. The per-reply time drops from 60 to 90 seconds to 30 to 45 seconds, the tab-switch is removed entirely, and the cadence is sustainable at 5 to 10 per day across two or three concentric attention circles (large accounts the writer replies to for surface area, peer accounts for relationship density, smaller accounts for cohort-building). The VoiceMoat Chrome extension at voicemoat.com/extension runs this workflow at the voice-rich side of the split; the closer placement in the broader Chrome-extension category is at the 10 best Chrome extensions for Twitter/X creators in 2026.
Four illustrative reply examples (constructed, labeled)
Four illustrative reply pairs below. All examples are constructed for this piece, not lifted from any specific creator's actual replies. Each pair shows the original post (illustrative), a generic-AI-reply version (the failure mode), and a voice-rich AI-drafted-and-edited version (the right move). The pairs are constructed examples, clearly labeled, not real replies.
Pair 1: a take on remote work
Original post (illustrative): "The remote-vs-office debate is solved if you measure outcomes instead of hours."
Generic-AI-reply (illustrative, failure mode): "This is so true! Outcomes-based management is the future of work. Great point!" The reply reads as generic-AI-shaped because it agrees without adding signal; the audience pattern-matches it as automation within seconds. The writer's reputational capital decays a fraction with each reply of this shape.
Voice-rich AI-drafted-and-edited reply (illustrative, right move): "True for individual contributors. Trickier for managers because outcomes are harder to define per-week when the manager's job is to make the team's outcomes possible rather than ship outcomes directly. The shift to outcomes-first measurement works at the IC layer and breaks at the management layer unless the measurement explicitly accounts for second-order outcomes." The reply reads as voice-rich because it engages with the specific take, adds a layer the original did not surface, and the engagement is specific enough that the audience reads it as the writer thinking rather than as a praise-response.
Pair 2: a thread on writing voice
Original post (illustrative, thread opener): "Most writers think their voice is what they say. Their voice is actually how they say it."
Generic-AI-reply (illustrative, failure mode): "100% agree. Writing voice is everything. Looking forward to the rest of the thread!" The reply is content-free agreement plus a generic anticipation hook. The audience pattern-matches it as automation; the writer who posts replies of this shape across hundreds of threads accumulates an audience read on their account as not-a-real-engagement.
Voice-rich AI-drafted-and-edited reply (illustrative, right move): "The how-they-say-it is also where most voice training fails. Tools that train on a writer's published corpus learn the topics and the surface vocabulary but miss the cadence and the formatting quirks that make the voice recognizable. Voice is a stack, not a vocabulary, and most tooling stops at vocabulary." The reply reads as voice-rich because it engages with the underlying claim, extends it with a specific operational point, and the extension is the writer's own observation rather than agreement.
Pair 3: a build-in-public revenue post
Original post (illustrative): "Hit $50K MRR this month. Three years in. The slowest part was the first $5K."
Generic-AI-reply (illustrative, failure mode): "Congrats on the milestone! Amazing achievement! The journey is everything!" The reply is generic celebration with no specificity. The audience pattern-matches the shape as automation; the writer's reputational capital decays a fraction. The build-in-public author also notices the shape after seeing dozens of similar replies and pattern-matches the replier as not-a-real-engagement.
Voice-rich AI-drafted-and-edited reply (illustrative, right move): "The first $5K being the slowest part is the universal pattern across every build-in-public retro I have read this year. The interesting variable is what specifically broke through the floor: in your case I would guess it was either a distribution channel that started compounding or a pricing change that unlocked a customer segment that was hovering. Which one was it?" The reply reads as voice-rich because it surfaces a specific question that the original would actually want to answer, and the question is the kind of question a peer would ask rather than a generic-engagement-bait question.
Pair 4: a hot take you partly disagree with
Original post (illustrative): "Cold email is dead. If you're still sending cold emails in 2026 you're behind."
Generic-AI-reply (illustrative, failure mode): "Couldn't agree more! Cold email is so outdated. Great take!" The reply agrees reflexively and adds nothing; the writer who reflexively agrees with every hot take accumulates an audience read on the account as a validation bot, which is the same reputational decay as the praise-response failure mode.
Voice-rich AI-drafted-and-edited reply (illustrative, right move): "Half-agree. Cold email is dead for spray-and-pray, but a researched three-line email to someone whose work you actually read still converts better than almost any channel I have tested this year. What died is the volume play, not the medium." The reply reads as voice-rich because it disagrees with a specific nuance rather than affirming, and a specific, respectful disagreement is one of the most underrated ways to be remembered. Voice-rich does not mean agreeable; it means the writer's actual reaction, which is sometimes a no.
What should you actually say in a reply?
The failure mode is generic praise; the fix is adding a specific kind of value. Six reply types carry their weight, and the strongest replies often combine two. The inline drafts give you a starting point, but choosing the type stays human, because it depends on what you specifically know that the original author and the onlookers do not.
- Data. Add a number, a benchmark, or a result the post did not have. Specific figures are the most screenshot-able reply type.
- Experience. Say what actually happened when you tried the thing the post is about. First-person specifics are hard to fake and easy to trust.
- Extension. Take the claim one step further, to the case it did not cover or the second-order effect it implied. This is the 'yes, and' that reads as thinking rather than agreeing.
- Question. Ask the specific question the author would actually want to answer, not engagement-bait. A good question invites a reply from the author, which is the strongest relationship signal there is.
- Contrarian. Disagree with a specific nuance, respectfully. The counterpoint is more memorable than the tenth agreement, and contrarian replies are widely reported to outengage agreement replies (treat the exact multiplier as directional, since most of that data is vendor-self-reported).
- Resource. Point to the specific study, tool, or thread the reader of the original post would want next. Useful beats clever.
Operational discipline that compounds reputational capital
Three operational disciplines hold the reply cadence on the voice-rich side of the split over months and years. Each one is small in isolation; together they are what separates the writer whose replies compound from the writer whose replies decay.
- Voice-rich cadence cap. Hold the cadence where the per-reply edit step still happens: 5 to 10 a day to build the habit, up to 15 to 20 once the edit step is reflexive (see the volume section above). The cap is the structural defense against the volume-at-scale failure mode; below it the writer has the time-budget to read each post carefully and edit each draft for voice, and above it the workflow collapses into auto-generation or skimming. It is a hard discipline, not a soft preference.
- Per-reply edit step held real. Every voice-trained reply draft gets a 10-to-20-second edit pass before it ships. The edit catches the patterns the voice training missed (the specific post-context the draft did not account for, the formatting quirk the writer would have used, the line of thinking the draft started but did not finish). The edit step is what keeps the reply on the voice-rich side; without it, the replies converge on the voice-trained baseline rather than the writer's specific voice on that specific post.
- Reply target list as private lists. Build the reply target list as three concentric circles (large accounts for surface area, peer accounts for relationship density, smaller accounts for cohort-building) maintained as private X lists. Read the lists daily. Reply where the writer has something specific to say. Skip the rest. The list-driven workflow keeps the writer's replies targeted at posts the writer has genuine context on; replying to random feed posts at scale collapses into the generic-engagement failure mode.
- Disagreement budget. Spend some of your replies on specific, respectful disagreement, not only agreement. The reply that adds a counterpoint is more memorable than the tenth reply that agrees, and an account that only ever affirms reads as a validation bot even when a human writes every reply. Voice-rich does not mean sycophantic; it means the writer's actual reaction, which is sometimes a no.
- Reply early, to posts that are still small. A reply is seen only if it lands while the post is climbing and before the replies stack up, so reply in the first 5 to 15 minutes (turn on notifications for your target list) and favor posts with a handful of existing replies over ones with hundreds. Reply to accounts several times your size, where the distribution you are borrowing actually exists; a brilliant reply on a post no one is reading earns nothing. Timing and post-selection are half the result, the reply itself is the other half.
A concrete starting protocol: build the three lists this week (roughly ten large accounts, fifteen peers, twenty smaller accounts in your niche), then reply to three posts a day where you have a specific reaction, using the inline drafts as a starting point and editing each for the specific post. Three a day is under the cap on purpose; the goal in the first month is to make the edit step automatic before scaling volume, because a habit of shipping unedited drafts at ten a day is harder to unlearn than a habit of editing at three a day is to scale. Raise the cadence toward the 5-to-10 cap only once the edit step is reflexive.
What about using ChatGPT or Claude for replies?
The honest alternative most reply-guys actually weigh is not a dedicated reply tool; it is a general assistant they already pay for. ChatGPT and Claude can both draft a reply if you paste the original post and ask, and for a writer with an already-durable voice they work as a thinking partner. The reason they do not hold up at reply cadence is specific: a general assistant is optimized to be maximally helpful to anyone, so its default reply gravitates to the competent-but-anonymous helpful-assistant register, which is the exact register the audience pattern-matches as not-you within a scroll. At one reply that is survivable; at 5 to 10 a day for months it is the slow version of the voice-corrosive failure mode.
You can push a general model closer with custom instructions and pasted voice samples, but then you are doing the voice work by hand on every reply, which is the cost the inline voice-trained workflow exists to remove, and the tab-switch to a separate chat window reintroduces the cadence-killer from the section above. The deeper read on why general models converge on the same register regardless of prompting is at why all AI-written tweets sound the same, and the head-to-head on the two leading general models for writing is at Claude vs ChatGPT for content writing in 2026. The short version for replies: a general assistant is fine for thinking about what to say, but the published reply has to sound like you, and that is the voice-trained tool's job.
What the right reply workflow deliberately is not
Three categories the voice-rich reply workflow deliberately omits. Each one is operational discipline that defends reputational capital at the load-bearing layer.
First, it is not auto-engagement at the follow / unfollow / like layer. Auto-engagement amplifies the same reputational-collapse mechanism as auto-reply because the audience pattern-matches the engagement signal as automated within the same observation window. The writer who runs auto-engagement plus voice-rich manual replies still loses reputational capital from the engagement layer.
Second, it is not high-volume reply automation at scale. The case against is at the voice-corrosive-versus-voice-rich split above; the volume-at-scale workflow is structurally incompatible with the voice-rich cadence cap.
Third, it is not general AI writing assistants used for replies without voice training; the reputational-capital reasons are in the dedicated section above. The cost-per-month differential between a general AI tool and a voice-trained tool is dwarfed by the reputational-capital value the voice-trained workflow protects, and running the cadence on a real-time-prompted general model reintroduces both the helpful-assistant register and the tab-switch.
Which bot-shape patterns does the audience actually catch?
Before the self-check, the concrete patterns the audience pattern-matches as automation. None of these needs a detector tool; human-level pattern recognition catches all of them within a few weeks of observation. Each one is a structural signature, not a content judgment, which is why a human can produce them by hand and still read as a bot.
- Instant timing. A reply that lands within 30 seconds of every targeted post, every time, reads as a script watching a feed rather than a human reading a post.
- Repeated opening structures. The same three or four opening moves ("This is so true," "Great point," "Couldn't agree more") across hundreds of replies is the single most catchable signature.
- Praise without signal. A reply that affirms but adds nothing the original did not already say. The audience reads affirmation-only replies as engagement-farming.
- Portability. A reply that could sit under a dozen unrelated posts without anyone noticing. Welded-to-the-specific-post is the opposite signal.
- Volume without depth. Fifty replies a day that are each one generic sentence reads as automation even if a human typed all fifty.
- Identical sign-offs or a fixed emoji. A standard closing flourish on every reply is a template tell.
How do you tell if your AI replies already read as bot-shaped?
A fast self-check the writer can run before the audience runs it for them: pull your last 20 replies into one view and ask whether each one could be pasted under a different original post without anyone noticing. A voice-rich reply is welded to the specific post it answers; it cannot be moved. A bot-shaped reply is interchangeable, which is the exact signature the audience pattern-matches as a social bot. If more than a few of your last 20 replies are portable across unrelated posts, the replies are already reading as automated even if a human wrote every one. The engagement-behavior data platforms and analysts track (see Hootsuite's running X/Twitter statistics) is consistent on the direction: reply engagement compounds for accounts the audience reads as genuine and flatlines for accounts it reads as automated, regardless of raw reply volume.
This is where the voice-match measurement layer earns its place. A voice-trained reply draft that scores high on voice match is one the audience is more likely to read as the writer rather than as a reply bot, and the per-draft score is the gate that catches drift before a portable, interchangeable reply ships. Auden trains on the writer's full profile across the 10 signals of voice, so the reply draft starts welded to the writer's register rather than to a generic-engagement template; the edit step then welds it to the specific post. The deeper read on whether audiences can actually tell the difference is at can your audience tell you're using AI.
How do you measure whether your replies are compounding?
The portability test above catches bot-shape; a second set of signals tells you whether the replies are actually compounding. Track four things over a month, not a day: profile visits that arrive from your replies (the reply did its job if it sent someone to your profile), follows attributed to a reply rather than a post, replies that turn into a threaded back-and-forth with the original author (conversation depth is the strongest relationship signal), and the rate at which the accounts you reply to start replying to your posts (reciprocity is the compounding flywheel). If those four are flat or falling while your raw reply count rises, you are on the voice-corrosive side even if every reply was hand-written.
The leading per-reply quality gate is the voice match score: a voice-trained draft that scores high is one the audience is more likely to read as you rather than as a reply bot, and the score trend over weeks is an early-warning system for drift before the audience-level signals move. Auden trains on the writer's full profile across the 10 signals of voice, so a reply draft starts welded to the writer's register rather than to a generic-engagement template; the per-draft score is the gate, and the edit step is the weld to the specific post.
The one-line answer
How to use AI for Twitter replies without sounding like a bot in 2026 is the workflow on the voice-rich side of the structural split: voice-trained reply drafts surfaced inline on x.com via a Chrome extension, edited by the writer for 10 to 20 seconds per reply, shipped at a cadence the per-reply edit step can sustain (5 to 10 a day to start, up to 15 to 20 with reflexive editing) across three concentric attention circles maintained as private X lists, replying early to posts still gathering replies. The voice-corrosive side (automation-first reply tooling at 30 to 100 per day, auto-engagement at the follow / unfollow / like layer, general AI writing assistants without voice training) collapses reputational capital faster than any other content failure mode because the audience pattern-matches the volume-at-scale signature as bot within weeks of observation. The illustrative reply pairs above show the failure mode (generic-AI-reply that the audience pattern-matches as automation) versus the right move (voice-rich AI-drafted-and-edited reply that compounds reputational capital). The omissions (auto-engagement, high-volume reply automation, general AI tools without voice training) are operational discipline at the load-bearing layer.
If you reply-guy on X and you want voice-trained reply drafting inline on x.com without the tab-switch that kills the cadence, Auden, the brain inside VoiceMoat, trains on your full profile of 100 to 200 posts, replies, threads, and images across the 10 signals of voice. The VoiceMoat Chrome extension at voicemoat.com/extension surfaces three voice-trained reply drafts across 12 tone presets directly on x.com, with sub-2-second generation per draft. Auden refuses the AI vocabulary cluster (leverage, delve, unlock, navigate, harness, foster, elevate, embark, robust, seamless, comprehensive, holistic) at the model level. Auden suggests. You decide.